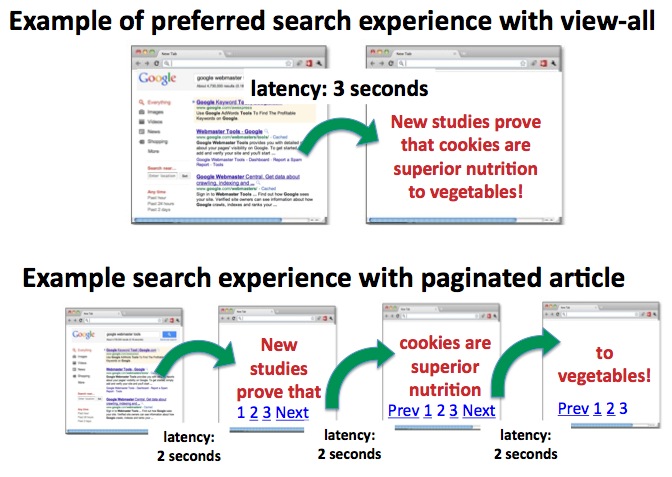
Webmaster level: All
We consistently hear from webmasters that they have to prioritize their time. Some manage dozens or hundreds of clients’ sites; others run their own business and may only have an hour to spend on website maintenance in between managing finances and inventory. To help you prioritize your efforts, Webmaster Tools is introducing the idea of “site health,” and we’ve redesigned the Webmaster Tools home page to highlight your sites with health problems. This should allow you to easily see what needs your attention the most, without having to click through all of the reports in Webmaster Tools for every site you manage.
Here’s what the new home page looks like:

You can see that sites with health problems are shown at the top of the list. (If you prefer, you can always switch back to listing your sites alphabetically.) To see the specific issues we detected on a site, click the site health icon or the “Check site health” link next to that site:
or the “Check site health” link next to that site:

This new home page is currently only available if you have 100 or fewer sites in your Webmaster Tools account (either verified or unverified). We’re working on making it available to all accounts in the future. If you have more than 100 sites, you can see site health information at the top of the Dashboard for each of your sites.
Right now we include three issues in your site’s health check:
A word about “important pages:” as you know, you can get a comprehensive list of all URLs that have been removed by going to Site configuration > Crawler access > Remove URL; and you can see all the URLs that we couldn’t crawl because of robots.txt by going to Diagnostics > Crawl errors > Restricted by robots.txt. But since webmasters often block or remove content on purpose, we only wanted to indicate a potential site health issue if we think you may have blocked or removed a page you didn’t mean to, which is why we’re focusing on “important pages.” Right now we’re looking at the number of clicks pages get (which you can see in Your site on the web > Search queries) to determine importance, and we may incorporate other factors in the future as our site health checks evolve.
Obviously these three issues—malware, removed URLs, and blocked URLs—aren’t the only things that can make a website “unhealthy;” in the future we’re hoping to expand the checks we use to determine a site’s health, and of course there’s no substitute for your own good judgment and knowledge of what’s going on with your site. But we hope that these changes make it easier for you to quickly spot major problems with your sites without having to dig down into all the data and reports.
After you’ve resolved any site health issues we’ve flagged, it will usually take several days for the warning to disappear from your Webmaster Tools account, since we have to recrawl the site, see the changes you’ve made, and then process that information through our Web Search and Webmaster Tools pipelines. If you continue to see a site health warning for that site after a week or so, the issue may not have been resolved. Feel free to ask for help tracking it down in our Webmaster Help Forum... and let us know what you think!
We consistently hear from webmasters that they have to prioritize their time. Some manage dozens or hundreds of clients’ sites; others run their own business and may only have an hour to spend on website maintenance in between managing finances and inventory. To help you prioritize your efforts, Webmaster Tools is introducing the idea of “site health,” and we’ve redesigned the Webmaster Tools home page to highlight your sites with health problems. This should allow you to easily see what needs your attention the most, without having to click through all of the reports in Webmaster Tools for every site you manage.
Here’s what the new home page looks like:

You can see that sites with health problems are shown at the top of the list. (If you prefer, you can always switch back to listing your sites alphabetically.) To see the specific issues we detected on a site, click the site health icon

This new home page is currently only available if you have 100 or fewer sites in your Webmaster Tools account (either verified or unverified). We’re working on making it available to all accounts in the future. If you have more than 100 sites, you can see site health information at the top of the Dashboard for each of your sites.
Right now we include three issues in your site’s health check:
- Have we detected malware on the site?
- Have any important pages been removed via our URL removal tool?
- Are any of your important pages blocked from crawling in robots.txt?
A word about “important pages:” as you know, you can get a comprehensive list of all URLs that have been removed by going to Site configuration > Crawler access > Remove URL; and you can see all the URLs that we couldn’t crawl because of robots.txt by going to Diagnostics > Crawl errors > Restricted by robots.txt. But since webmasters often block or remove content on purpose, we only wanted to indicate a potential site health issue if we think you may have blocked or removed a page you didn’t mean to, which is why we’re focusing on “important pages.” Right now we’re looking at the number of clicks pages get (which you can see in Your site on the web > Search queries) to determine importance, and we may incorporate other factors in the future as our site health checks evolve.
Obviously these three issues—malware, removed URLs, and blocked URLs—aren’t the only things that can make a website “unhealthy;” in the future we’re hoping to expand the checks we use to determine a site’s health, and of course there’s no substitute for your own good judgment and knowledge of what’s going on with your site. But we hope that these changes make it easier for you to quickly spot major problems with your sites without having to dig down into all the data and reports.
After you’ve resolved any site health issues we’ve flagged, it will usually take several days for the warning to disappear from your Webmaster Tools account, since we have to recrawl the site, see the changes you’ve made, and then process that information through our Web Search and Webmaster Tools pipelines. If you continue to see a site health warning for that site after a week or so, the issue may not have been resolved. Feel free to ask for help tracking it down in our Webmaster Help Forum... and let us know what you think!